წინა სტატიაში განვიხილეთ ცვლადებისა და ფუნქციების შემოღება test plan-ის ფარგლებში, სხვადასხვა ელემენტების პარამეტრებში. რაც საბოლოოდ გაცილებით კარგ შედეგს გვაძლევს ვიდრე “ერთ ამოჩებულ” request URL-ზე მოთხოვნების გაგზავნა. თუმცა რეალურ სამუშაო გარემოში performance testing მოითოვს გარკვეული რაოდენობის, წინასწარ მოცემული მომხმარებლების/მონაცემების გამოყენებას, რაც მარტივი counter და random ცვლადი/ფუნქციით შეუძლებელია.
სწორედ აქ შემოდის Config Element სახელად CSV Data Set Config

სანამ გადავალთ უშუალოდ მაგალითებზე და მუშაობის პრინციპზე/ დამუშავების ვარიანტებზე, ბევრს გაუჩნდებოდა კითხვა:
რატომ CSV და არა სხვა ფორმატი?
სამი ძირითადი მიზეზი:
მარტივად დამუშავებადია— ოპერაციები მონაცემებზე ხორციელდება Excel-ს მოქნილობით;
არის ტექსტური ტიპის და მსუბუქად დასამუშავებელი. performance თვალსაზრისით სწრაფია;
წონა — იგივე Excel-თან შედარებით მოცულობით გაცილებით მცირე ზომისაა.
და მაინც, რატომ დამჭირდება ფაილიდან მონაცემების წაკითხვა, თუკი random და counter ისეც “გააფერადებს” request-ებს?
არის სიტუაციები, როდესაც უნდა ვემუშაოთ კონკრეტულ სიებს და random-ად აღებული მონაცემები არ მოგვცემს სასურველ შედეგს.
შესაძლებელია 2 ან მეტი tread group-ის კოლაბორაცია. მაგალითად: Thread1-ით შევინახოთ მონაცემები CSV ფაილში და Tread2-ში გამოვიყენოთ ეს მონაცემები მომდევნო ტესტისთვის.
ვფიქრობ ყველაზე ეფექტური სწავლების მეთოდია კონკრეტული მაგალითები, ანუ სიმარტივე მაგალითებშია:)
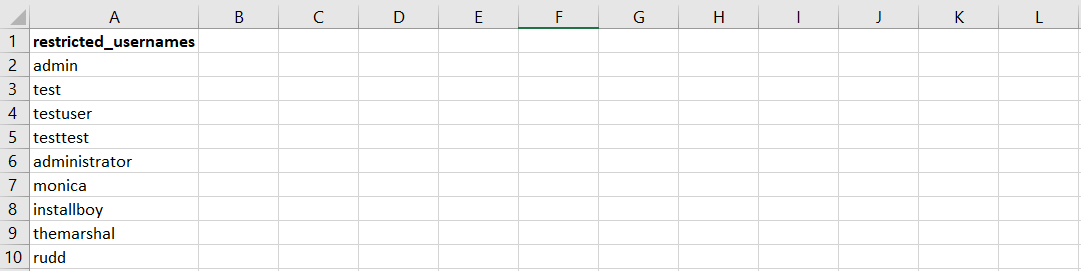
გვაქვს ამოცანა: ვამოწმებთ შეზღუდული სახელების(username) მომხმარებლების სიას, არის თუ არა რომელიმე ჩანაწერი უკვე გამოყენებული. სიაშია 500 ვარიანტი(მაგალითად: test, testuser, admin, administrator და ა.შ.).
1. Test Plan-ში ვამატებთ ელემენტს CSV Data Set Config
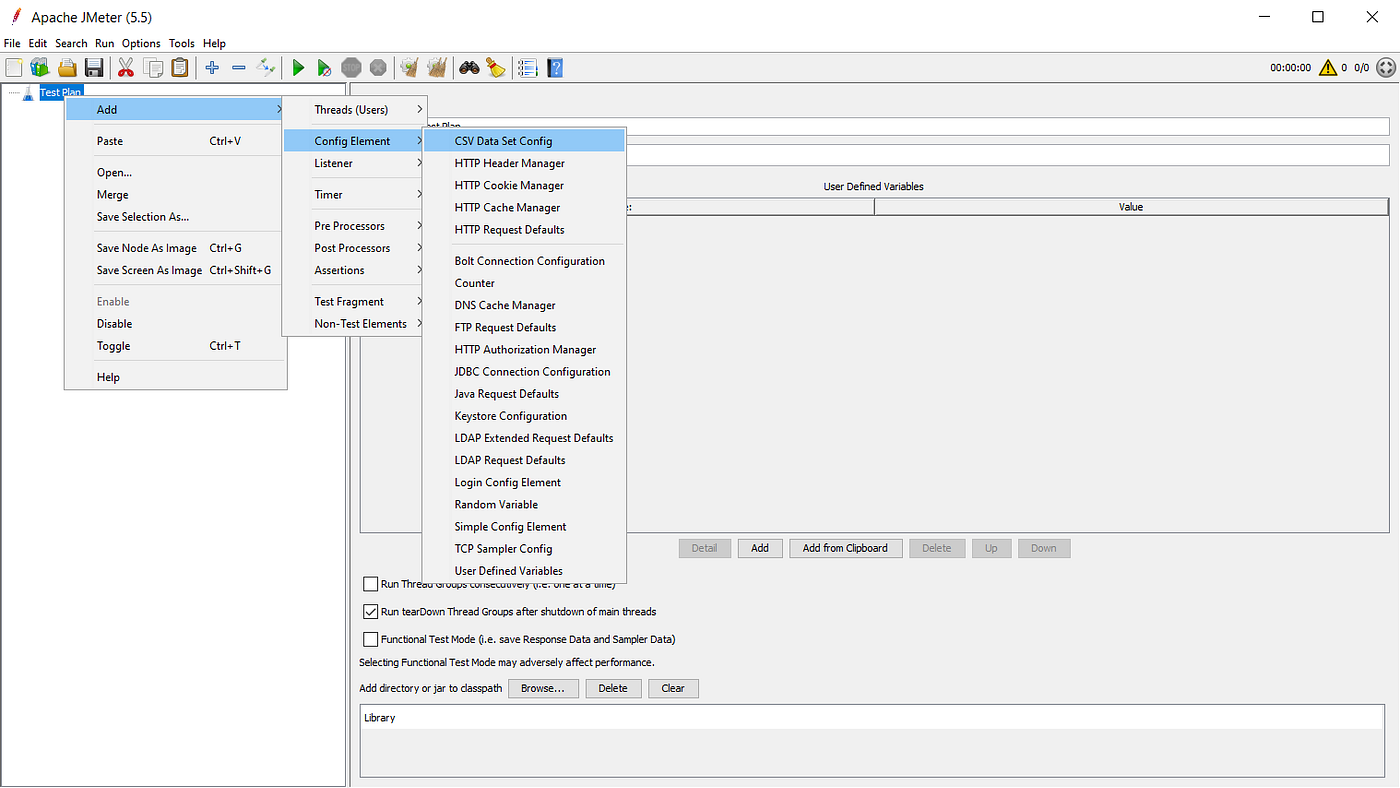
2. ვირჩევთ ფაილს, სადაც გვაქვს წინასწარ გაწერილი მომხმარებლები და შემოგვაქვს ცვლადი, რომელიც იქნება გამოყენებული username-ების გამოსატანად
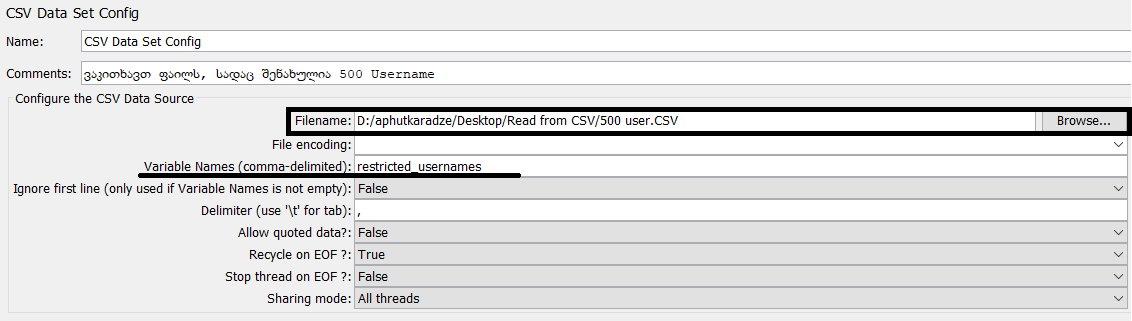
ფაილი გამოიყურება შემდეგნაირად:
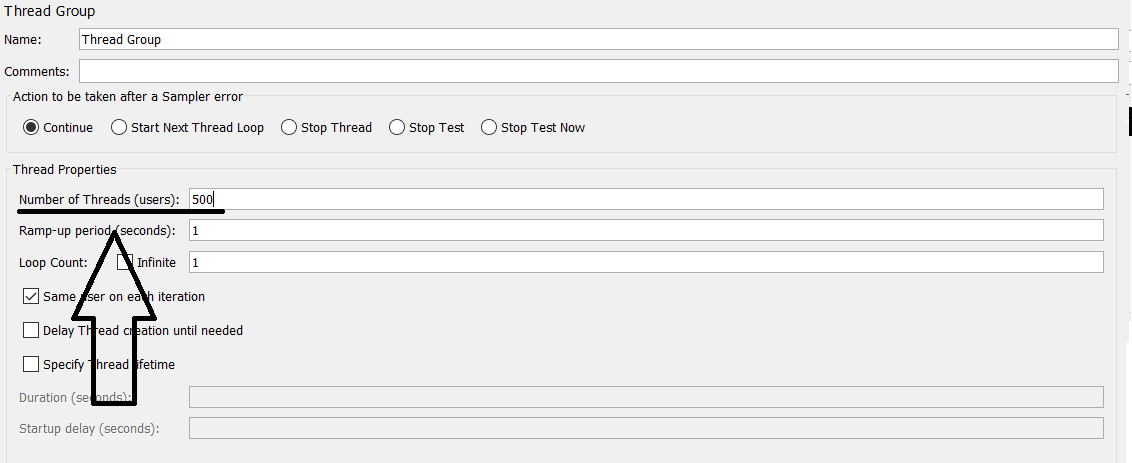
3. ვამატებთ Thread Group-ს, სადაც შესაბამისი რაოდენობის sampler-ის გასაშვებად number of threads(users)-ში ვუთითებ 500-ს
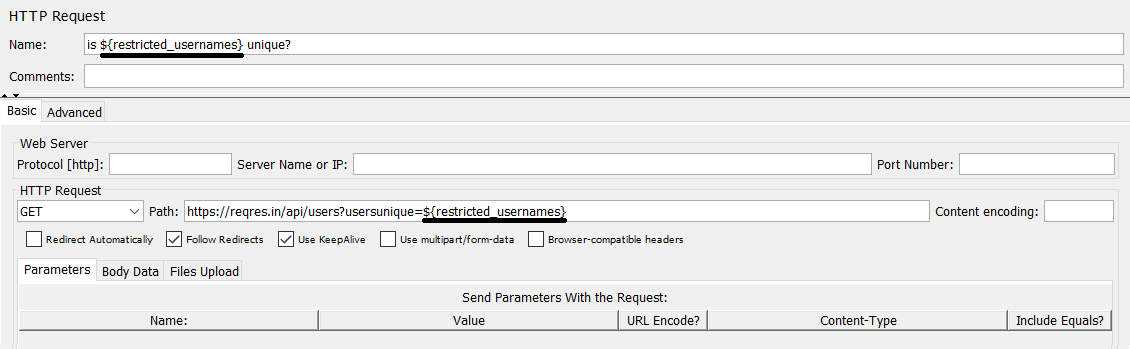
4. ვამატებ HTTP Request ელემენტს, სადაც:
მეთოდია GET, მისამართი https://reqres.in/api/users?usersunique= და მომხმარებლის ნაცვლად, პარამეტრად ვიყენებთ CSV Data Set Config-ში გაწერილ ცვლადს(${restricted_usernames}). ასევე, თვალსაჩნოებისათვის Sampler-ის სახელშიც შემოგვაქვს იგივე ცვლადი.
5. მარტივი Listener, View Result Tree და Start 🙂
რა მივიღეთ?
500, განსხვავებული GET request, რომლითაც შევამოწმეთ იყო თუ არა გამოყენებული ფაილში მოცემული მომხმარებლები. ეს მისამართი იყო არარეალური და ვიდეოს ბოლოში შეამჩნევდით უბრალოდ Error Count:1-ს 🙂 ექსპერიმენტი ჩატარებულია თვალსაჩინოებისათვის.
მეორე, უფრო საინტერესო მაგალითი:
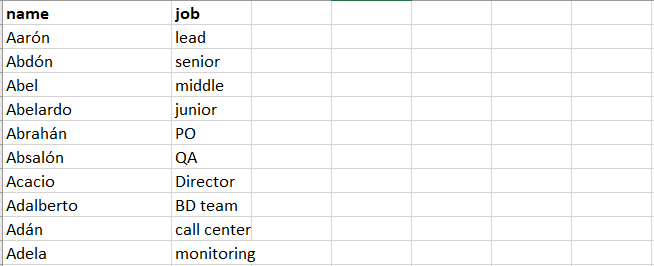
100 მომხმარებელი, რომელიც უნდა დაემატოს უკვე არსებულ მომხმარებელთა სიას. ამჯერად ემატება როგორც სახელი, ასევე სამუშაო პოზიცია. CSV ფაილშია ორი სვეტი(name, job).
წინა მაგალითის ანალოგიურად: CSV Data Set Config, Thread Group, HTTP Request(ამჯერად POST და ფაილიდან წამოღებული მონაცემებს ვუთითებთ body-ში) და View Result Tree
რა შედეგით დასრულდა ტესტი?
გაიგზავნა 100 POST request მისამართზე: ttps://reqres.in/api/users.
CSV Data Set Config-დან აღებული ორი ცვლადის(${name} და ${job}) გამოყენებით ყოველი Sampler მოიცავდა განსხვავებულ სახელსა და სამუშაო პოზიციას.
ფაილის წაკითხვისთვის არსებობს სხვა მეთოდებიც, მაგალითად: ფუნქციები გამოყენება, როგორიცაა __CSVRead, __StringFromFile;
While controler-ის შემოტანა.
მაგრამ სტატია არის დამწყებთათვის და ემსახურება მიზანს: იყოს მარტივად გასაგები.
ანალოგიური ამბავია, იგივე HTTP Request ელემენტზეც.
ბევრ სტატიაში/ვიდეოში მოცემული აქვთ ლინკის დაშლილი ვარიანტი:
Protocol + Server name + path — ცალკე ველებში.
თუმცა, როგორც პრაქტიკა აჩვენებს უმეტეს შემთხვევაში ყველაფრის გაერთიანება path-ში უპრობლემოდ მუშაობს.
ავტორი: anri.phutkaradze