დღეს მინდა ამ პოსტში თავი მოვუყარო გამოყენების და მაგალითების ნაკრებს xpath თან დაკავშირებით. როგორც წესი ხშირად ვიღებთ ელემენტებს არასწორი გზით (გართულებული და დაგრძელებული გზებით) რაც ხშირად იწვევს ნაკლებ წარმადობას და ნაკლებ სტაბილურობას.
პირველ რიგში გავარჩიოთ ერთი მარტივი უბრალო xpath სტრუქტურა, მაგალითად: სურათზე მოცემული სტრუქტურაში:
სურათზე მოცემული სტრუქტურაში:
‘//’ – გულისხმობს რომ ჩვენი ძებნის ელემენტი მოძებნოს სოურს კოდის ნებისმიერ ადგილას.
‘*’ – ნიშნავს თეგს (შესაძლებელია მის ადგილზე წარმოდგენილი იყოს ნებისმიერი თეგი მაგალითად: div, span და სხვა ათასი რჯულის თეგი, მაგრამ ამ შემთხვევაში * აღნიშავს რომ არ აქვს მნიშვნელობა თეგს და ის შეიძლება იყოს ნებისმიერი.
‘@attrubute’ – ატრიბუტში შეიძლება href, src და სხვა მრავალი. ატრიბუტის სახელის წინ ყოველთვის იწერება @ გარდა text() ის. (ტექსტეს ცოტა მოგვიანებით შევხებით)
‘value’ მნიშველობა კი ყოველთვის ზის ‘ ‘ – ში.
მაგალითისთვის გვახსოვდეს რომ არ არის მიღებული absolute path გამოყენება ასეთი სახით და ყოველთვის ჯობია გამოყენებული იქნას relation xpath რადგან ასეთი სახის absolute path არ არის სანდო პიროვნება : ) სილამაზეს და კაი ტიპობას რომ თავი დავანებოთ. როდესაც დეველოპერი რაიმე ელემენტს ჩაამატებს/ამოუღებს კოდში ჩვენი xpath ს სტრუქტურას შეცვლაც მოგვიწევს ჩვენ კიდევ მაზოხისტები ხომ არ ვართ ? :))))

ასევე არ უნდა დაგვავიწყდეს რომ შეგვიძლია გამოვიყენოთ სხვადასხვა სახის ლოგიკები მაგალითად:
// tag [ condition1 ] # მარტივი ლოგიკა რომელიც უკვე გავარჩიეთ ზემოთ
// tag [ condition1 and condition2] # ‘AND’ ლოგიკა რამელიც იყენებს 'და' კავშირს
// tag [ condition1 or condition2] # ‘OR’ ლოგიკა რომელიც იყენებს 'ან' კავშირს
// tag [ (condition1 or condition2) and condition3] # ‘AND’ + ‘OR’ ლოგიკა რომელიც იყენებს 'და' და 'ან' კავშირს
// tag [ condition1 ] / tag [ condition2 ] # Child ასე კი შვილობილი ელემენტიც მივუთითოთ
// tag [ condition1 ] // tag [ condition2 ] # Search მოვძებნოთ შვილობილი ელემენტი
მაგალითები:
// book [ genre="fiction" ] # Simple
// car [ color="red" and brand="Toyota" ] # ‘AND’ logic
// fruit [ type="apple" or color="yellow" ] # ‘OR’ logic
// student [ (grade="A" or grade="B") and age<20 ] # ‘AND’ + ‘OR’
// library [ location="downtown" ] / book [ genre="thriller" ] # Child
// house [ color="blue" ] // room [ type="kitchen" ] # Search through children
რომ არ იყოს გაურკვეველი ბოლო ორი საკითხიც დავაზუსტოთ:
სხვაობა “//” და “/” შორის
‘/’ – მიუთითებს პირდაპირ ელემენტზე
// library [ location="downtown" ] / book [ genre="thriller" ]
მაგრამ თუ downtown ში არის პირდაპირ book ელემენტი მაშინ გამოვიყენებთ ერთ ხაზს. 
ხოლო თუ მათ შორის არსებობს რამდენიმე ელემენტი მაშინ გამოვიყენებთ //.
ახლა გადავიდეთ უკვე xpath იმ ფუნქციებზე რომლის გამოყენებაც ხშირად გვიწევს მუშაობის პროცესში:
contains()
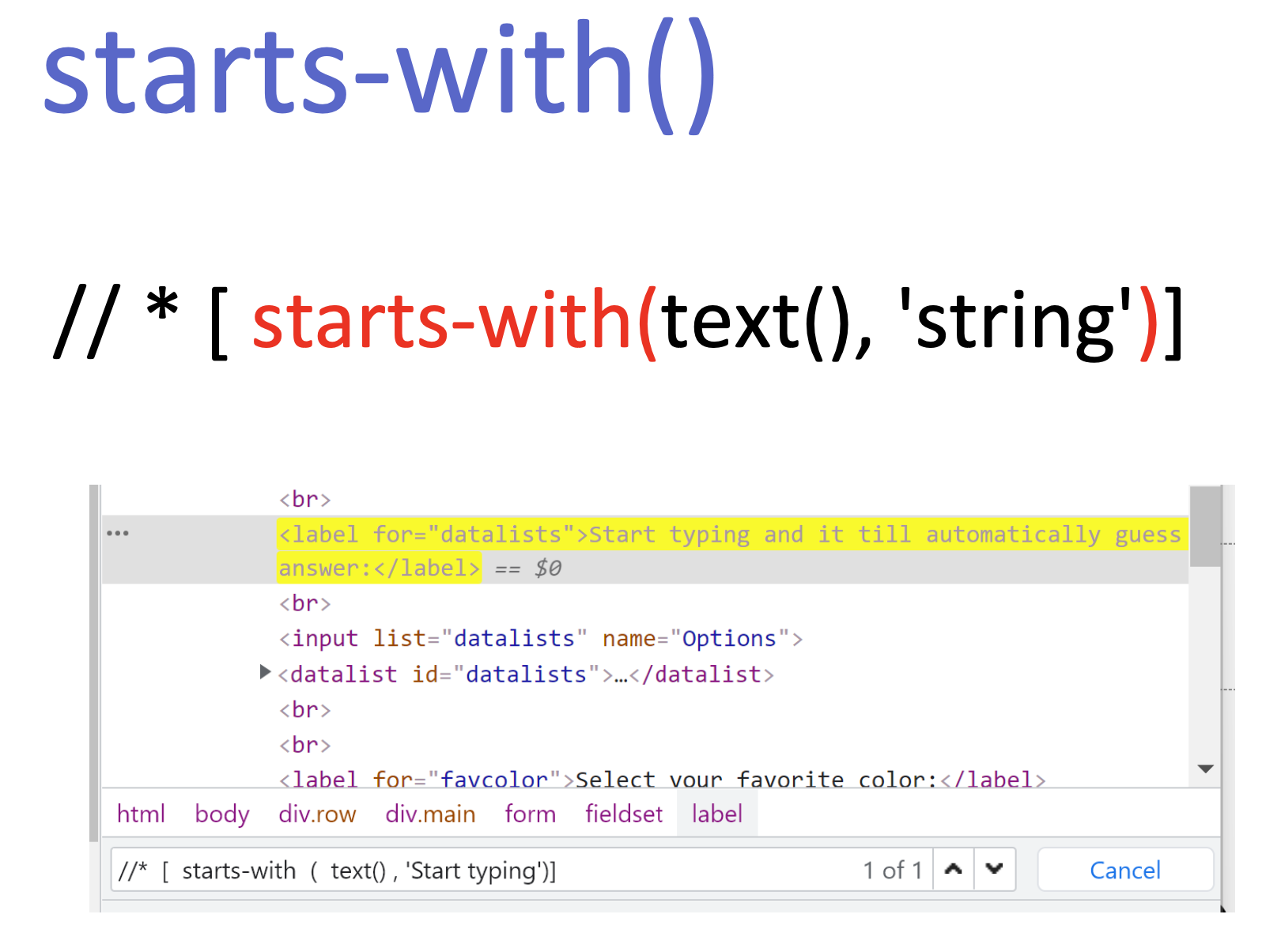
starts-with()
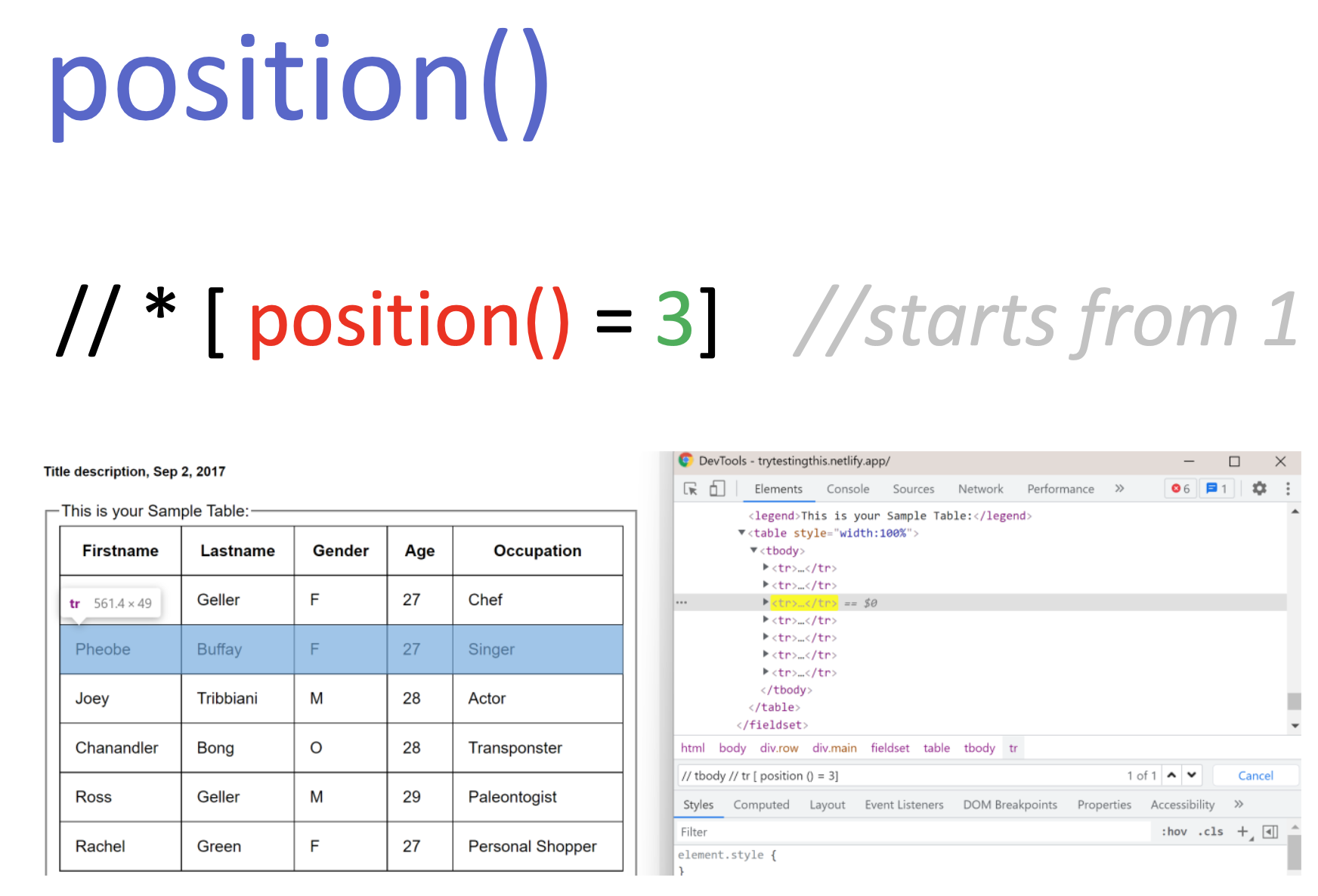
position()
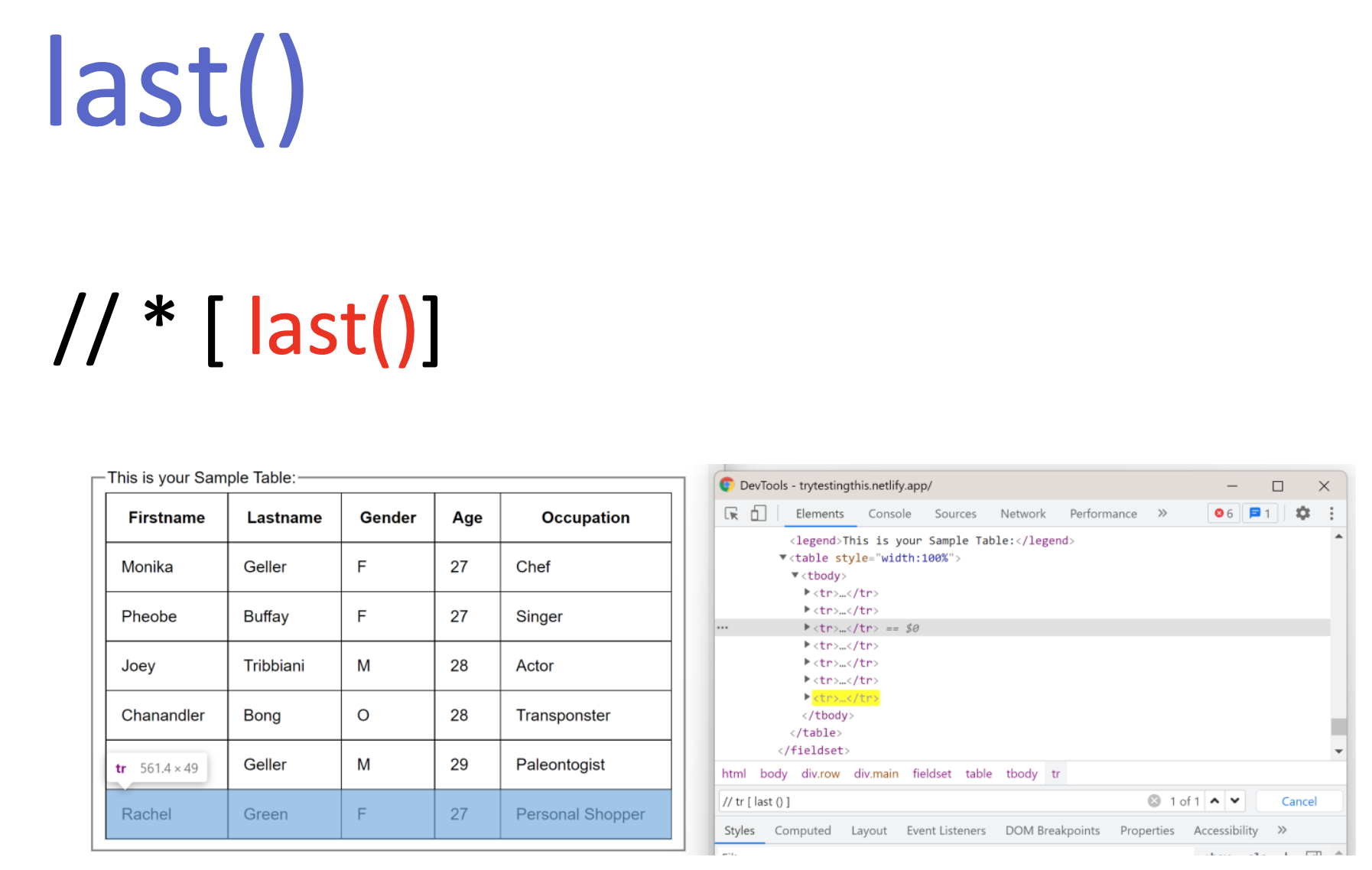
last()
normalize-space()
translate()
string-length()
round()
floor()
not()
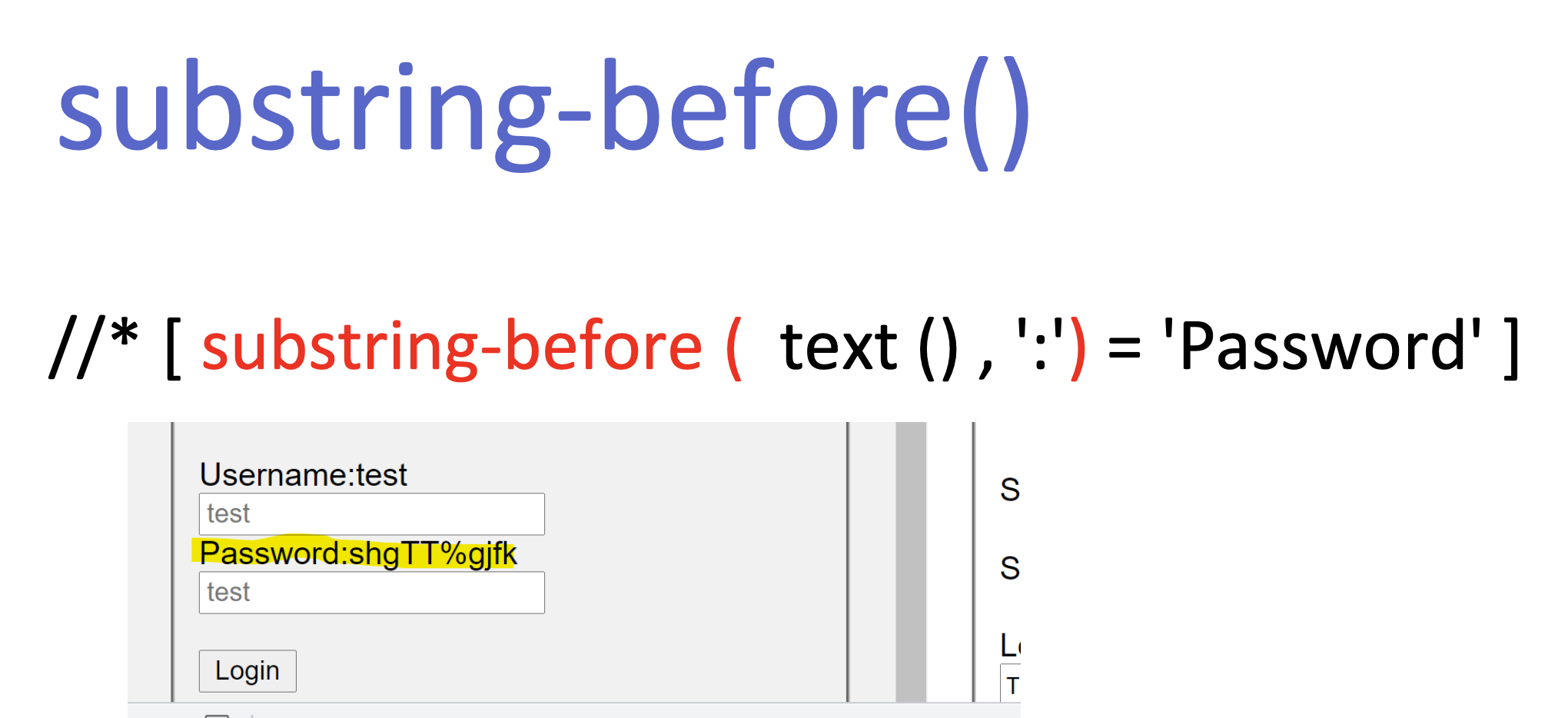
substring-before()
substring-after()
contains() // გვაძლევს საშუალებას შევამოწმოთ შეიცავს თუ არა განსაზღვრულ მნიშვნელობას კონკრეტული ელემენტი
// * [ contains(text(), 'string')]
// * [ contains(text(), 'string') and @id='some-id']
start-with() – შეგვიძლია შევამოწმოთ იწყება თუ არა კონკრეტული მნიშვნელობით.
position() – შეგვიძლია განვსაზღოთ პოზიცია
last() – ავიღოთ ბოლო ელემენტი
 ერთ ერთი ყველაზე ხშირად გამოყენებადი ფუნქცია რომელიც გამოიყენება მაშინ როდესაც არ ვიცით წინასწარ სტრინგის ზუსტი სახე, მაგალითად შეიცავს არასასურველ სფეისებს, გადატანილია მომდევნო ხაზზე და მსგავსი რამეები. მაგალითად გვაქვს
ერთ ერთი ყველაზე ხშირად გამოყენებადი ფუნქცია რომელიც გამოიყენება მაშინ როდესაც არ ვიცით წინასწარ სტრინგის ზუსტი სახე, მაგალითად შეიცავს არასასურველ სფეისებს, გადატანილია მომდევნო ხაზზე და მსგავსი რამეები. მაგალითად გვაქვს
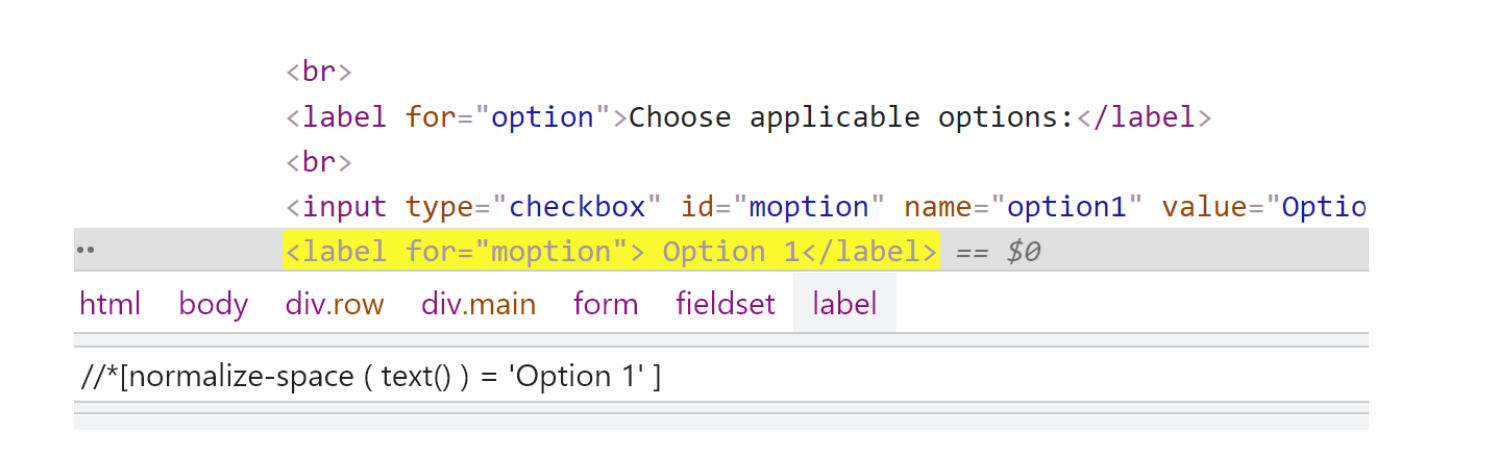
და შეგვიძლია ასე დავიჭიროთ 🙂

translate() –შეგვიძლია გამოვიყენოთ კონკრეტული სტრინგის გადასათარგმნათ, მაგალითად:
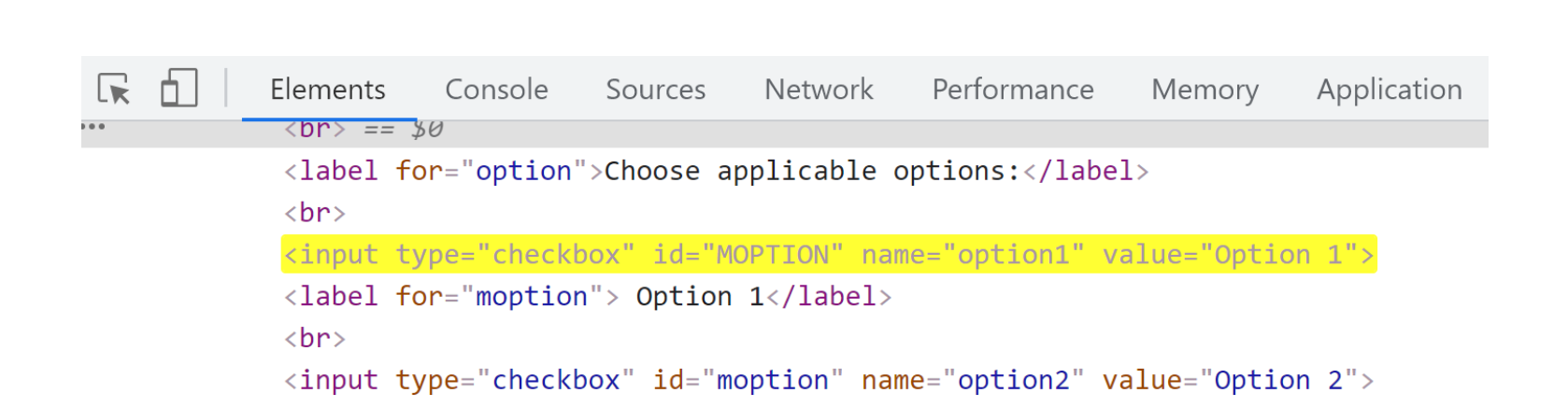 გვაქვს ასეთი რამ და არ გვინდა რომ ხელი შეგვიშალოს დიდ და პატარა ასოებმა :))) (როდესაც არ იცი წინასწარ როგორი იქნება ის)
გვაქვს ასეთი რამ და არ გვინდა რომ ხელი შეგვიშალოს დიდ და პატარა ასოებმა :))) (როდესაც არ იცი წინასწარ როგორი იქნება ის)
Option და option
 რა თქმა უნდა შესაძლებელია ფუნქციების გაერთიანებაც მაგალითად ასეთი რამე 🙂
რა თქმა უნდა შესაძლებელია ფუნქციების გაერთიანებაც მაგალითად ასეთი რამე 🙂
 string-length() გვაძლევს საშუალებას განვსაზღვროთ სტრიქონის ზომა.
string-length() გვაძლევს საშუალებას განვსაზღვროთ სტრიქონის ზომა.
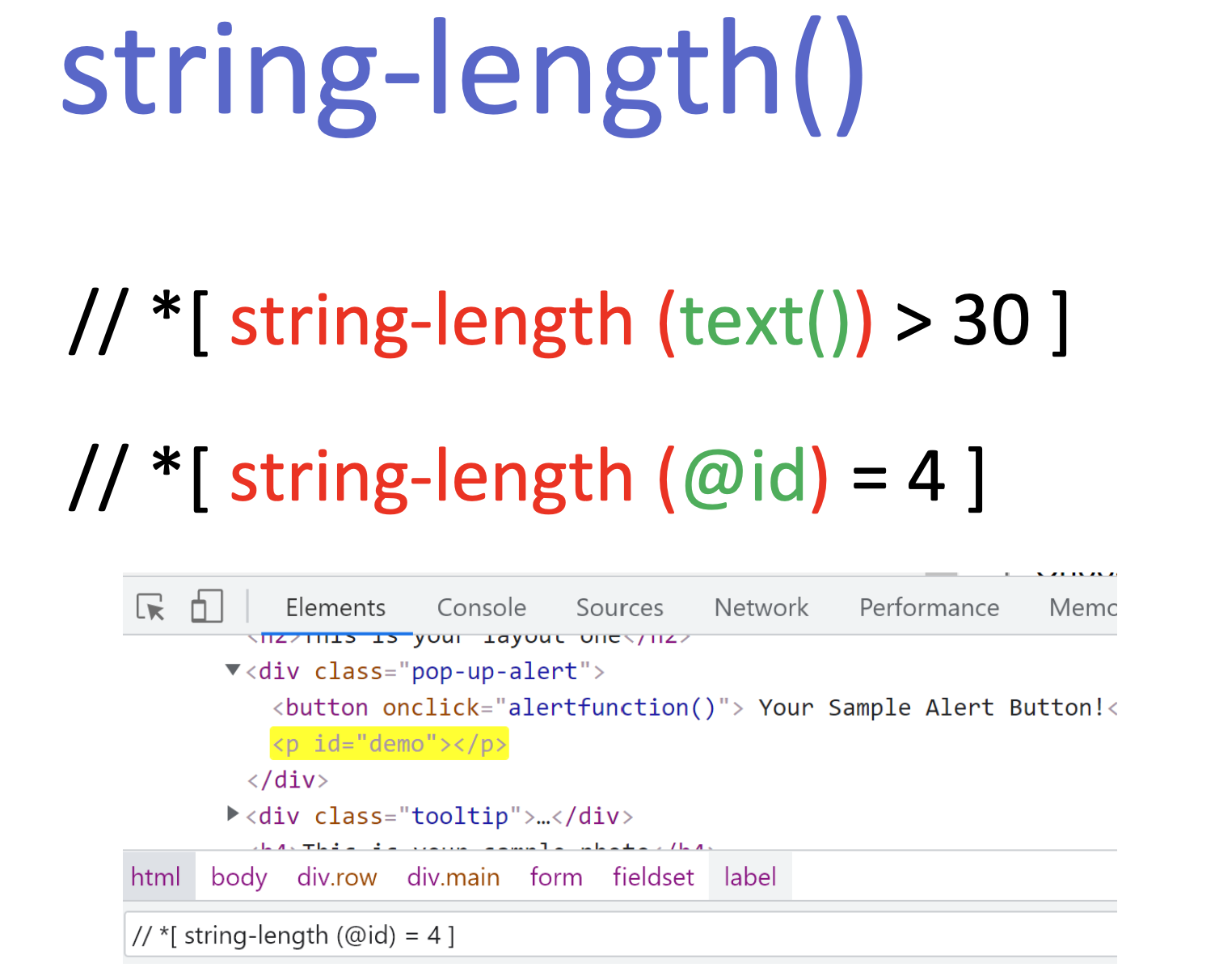
round() და floor() – ან უბრალოდ დავამრგვალოთ და ისე მოვძებნოთ 🙂


not() გამოვიყენოთ უარყოფა
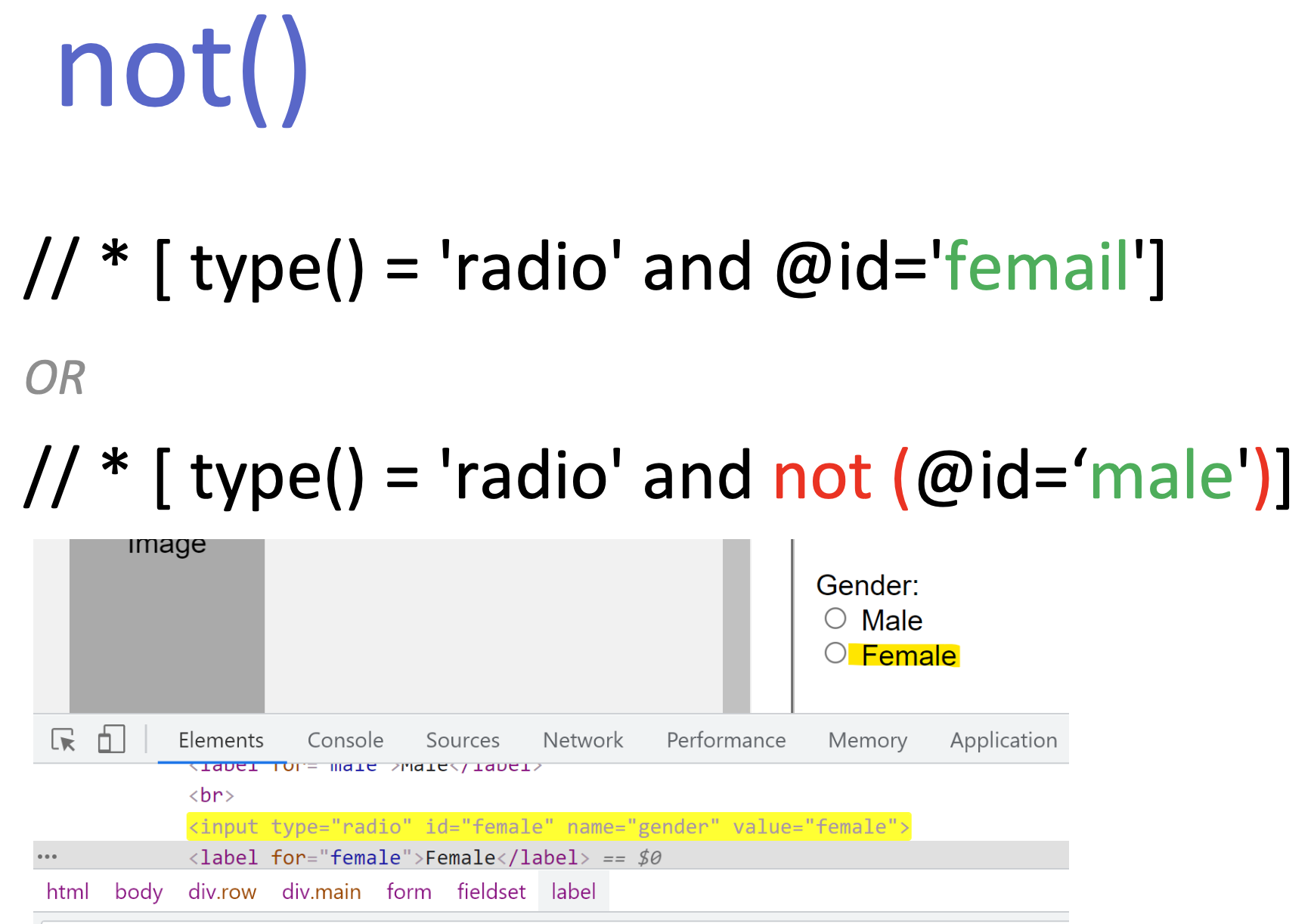
substring-before() და substring-after() გამოყენებით განვსაზღვროთ რითი იწყება ან მთავრდება სტრიქონი:

ეს არის ძირითადად მაგრამ არა სრულად და სრულყოფილად 🙂 არსებობს კიდევ ბევრი რამ სამომავლოდ მაგასაც გავაგრძელებთ 🙂


